File formats¶
Miller handles name-indexed data using several formats: some you probably know by name, such as CSV, TSV, JSON, JSON Lines, YAML, and DCF -- and other formats you're likely already seeing and using in your structured data.
Additionally, Miller gives you the option to include comments within your data.
Examples¶
mlr help file-formats
CSV/CSV-lite: comma-separated values with separate header line
TSV: same but with tabs in places of commas
+---------------------+
| apple,bat,cog |
| 1,2,3 | Record 1: "apple":"1", "bat":"2", "cog":"3"
| 4,5,6 | Record 2: "apple":"4", "bat":"5", "cog":"6"
+---------------------+
JSON (array of objects):
+---------------------+
| [ |
| { |
| "apple": 1, | Record 1: "apple":"1", "bat":"2", "cog":"3"
| "bat": 2, |
| "cog": 3 |
| }, |
| { |
| "dish": { | Record 2: "dish.egg":"7",
| "egg": 7, | "dish.flint":"8", "garlic":""
| "flint": 8 |
| }, |
| "garlic": "" |
| } |
| ] |
+---------------------+
JSON Lines (sequence of one-line objects):
+------------------------------------------------+
| {"apple": 1, "bat": 2, "cog": 3} |
| {"dish": {"egg": 7, "flint": 8}, "garlic": ""} |
+------------------------------------------------+
Record 1: "apple":"1", "bat":"2", "cog":"3"
Record 2: "dish:egg":"7", "dish:flint":"8", "garlic":""
YAML (single document = object or array of objects; multiple documents with ---):
+---------------------+
| apple: 1 |
| bat: 2 | Record 1: "apple":"1", "bat":"2", "cog":"3"
| cog: 3 |
| --- |
| dish: 7 | Record 2: "dish":"7", "egg":"8"
| egg: 8 |
+---------------------+
PPRINT: pretty-printed tabular
+---------------------+
| apple bat cog |
| 1 2 3 | Record 1: "apple:"1", "bat":"2", "cog":"3"
| 4 5 6 | Record 2: "apple":"4", "bat":"5", "cog":"6"
+---------------------+
Markdown tabular:
+-----------------------+
| | apple | bat | cog | |
| | --- | --- | --- | |
| | 1 | 2 | 3 | | Record 1: "apple:"1", "bat":"2", "cog":"3"
| | 4 | 5 | 6 | | Record 2: "apple":"4", "bat":"5", "cog":"6"
+-----------------------+
XTAB: pretty-printed transposed tabular
+---------------------+
| apple 1 | Record 1: "apple":"1", "bat":"2", "cog":"3"
| bat 2 |
| cog 3 |
| |
| dish 7 | Record 2: "dish":"7", "egg":"8"
| egg 8 |
+---------------------+
DKVP: delimited key-value pairs (Miller default format)
+---------------------+
| apple=1,bat=2,cog=3 | Record 1: "apple":"1", "bat":"2", "cog":"3"
| dish=7,egg=8,flint | Record 2: "dish":"7", "egg":"8", "3":"flint"
+---------------------+
DKVPX: delimited key-value pairs with CSV-style quoting
+----------------------------------+
| apple=1,bat=2,cog=3 | Record 1: "apple":"1", "bat":"2", "cog":"3"
| "x,y"="a,b,c",z=3 | Record 2: "x,y":"a,b,c", "z":"3"
+----------------------------------+
NIDX: implicitly numerically indexed (Unix-toolkit style)
+---------------------+
| the quick brown | Record 1: "1":"the", "2":"quick", "3":"brown"
| fox jumped | Record 2: "1":"fox", "2":"jumped"
+---------------------+
DCF: Debian control file format
+------------+
| apple: 1 |
| bat: 2 |
| cog: 3 |
| |
| dish: 7 |
| egg: 8 |
| 3: flint |
+------------+
CSV/TSV/ASV/USV/etc.¶
When mlr is invoked with the --csv or --csvlite option, key names are found on the first record, and values are taken from subsequent records. This includes the case of CSV-formatted files. See Record Heterogeneity for how Miller handles changes of field names within a single data stream.
Miller has record separator RS and field separator FS, just as awk does. (See also the separators page.)
CSV (comma-separated values): Miller's --csv flag supports RFC-4180 CSV.
- This includes CRLF line terminators by default, regardless of platform.
- Any cell containing a comma or a carriage return within it must be double-quoted.
TSV (tab-separated values): Miller's --tsv supports IANA TSV.
FSis tab andRSis newline (or carriage return + linefeed for Windows).- On input, if fields have
\r,\n,\t, or\\, those are decoded as carriage return, newline, tab, and backslash, respectively. - On output, the reverse is done -- for example, if a field has an embedded newline, that newline is replaced by
\n. - A tab within a cell must be encoded as
\t. - A carriage return within a cell must be encoded as
\n.
ASV (ASCII-separated values): the flags --asv, --iasv, --oasv, --asvlite, --iasvlite, and --oasvlite are analogous except they use ASCII FS and RS 0x1f and 0x1e, respectively.
USV (Unicode-separated values): likewise, the flags --usv, --iusv, --ousv, --usvlite, --iusvlite, and --ousvlite use Unicode FS and RS U+241F (UTF-8 0x0xe2909f) and U+241E (UTF-8 0xe2909e), respectively.
Here are the differences between CSV and CSV-lite:
-
CSV-lite naively splits lines on newline, and fields on comma -- embedded commas and newlines are not escaped in any way.
-
CSV supports RFC-4180-style double-quoting, including the ability to have commas and/or LF/CRLF line-endings contained within an input field; CSV-lite does not.
-
CSV does not allow heterogeneous data; CSV-lite does (see also Record Heterogeneity).
-
TSV-lite is simply CSV-lite with the field separator set to tab instead of a comma. In particular, no encoding/decoding of
\r,\n,\t, or\\is done. -
CSV-lite allows changing FS and/or RS to any values, perhaps multi-character.
-
CSV-lite and TSV-lite handle schema changes ("schema" meaning "ordered list of field names in a given record") by adding a newline and re-emitting the header. CSV and TSV, by contrast, do the following:
- If there are too few keys, but these match the header, empty fields are emitted.
- If there are too many keys, but these match the header up to the number of header fields, the extra fields are emitted.
- If keys don't match the header, this is an error.
cat data/under-over.json
[
{ "a": 1, "b": 2, "c": 3 },
{ "a": 4, "b": 5, "c": 6, "d": 7 },
{ "a": 7, "b": 8 },
{ "a": 9, "b": 10, "c": 11 }
]
mlr --ijson --ocsvlite cat data/under-over.json
a,b,c 1,2,3 a,b,c,d 4,5,6,7 a,b 7,8 a,b,c 9,10,11
mlr --ijson --ocsvlite cat data/key-change.json
a,b,c 1,2,3 4,5,6 a,X,c 7,8,9
mlr --ijson --ocsv cat data/under-over.json
a,b,c 1,2,3 4,5,6,7 7,8, 9,10,11
mlr --ijson --ocsv cat data/key-change.json
a,b,c 1,2,3 4,5,6 mlr: CSV schema change: first keys "a,b,c"; current keys "a,X,c" mlr: exiting due to data error
- In short, use-cases for CSV-lite and TSV-lite are often found when dealing with CSV/TSV files which are formatted in some non-standard way -- you have a little more flexibility available to you. (As an example of this flexibility: ASV and USV are nothing more than CSV-lite with different values for FS and RS.)
CSV, TSV, CSV-lite, and TSV-lite have in common the --implicit-csv-header flag for input and the --headerless-csv-output flag for output.
See also the --lazy-quotes flag, which can help with CSV files that are not fully compliant with RFC-4180.
JSON¶
JSON is a format which supports scalars (numbers, strings, booleans, etc.) as well as "objects" (maps) and "arrays" (lists), while Miller is a tool for handling tabular data only. By tabular JSON I mean the data is either a sequence of one or more objects, or an array consisting of one or more objects. Miller treats JSON objects as name-indexed records.
This means Miller cannot (and should not) handle arbitrary JSON. In practice,
though, Miller can handle single JSON objects as well as lists of them. The only
kinds of JSON that are unmillerable are single scalars (e.g., file contents 3)
and arrays of non-object (e.g., file contents [1,2,3,4,5]). Check out
jq for a tool that handles all valid JSON.
In short, if you have tabular data represented in JSON -- lists of objects,
either with or without outermost [...] -- [then Miller can handle that for
you.
Single-level JSON objects¶
An array of single-level objects is, quite simply, a table:
mlr --json head -n 2 then cut -f color,shape data/json-example-1.json
[
{
"color": "yellow",
"shape": "triangle"
},
{
"color": "red",
"shape": "square"
}
]
mlr --json head -n 2 then cut -f color,u,v data/json-example-1.json
[
{
"color": "yellow",
"u": 0.632170,
"v": 0.988721
},
{
"color": "red",
"u": 0.219668,
"v": 0.001257
}
]
Single-level JSON data goes back and forth between JSON and tabular formats in the direct way:
mlr --ijson --opprint head -n 2 then cut -f color,u,v data/json-example-1.json
color u v yellow 0.632170 0.988721 red 0.219668 0.001257
mlr --ijson --opprint cat data/json-example-1.json
color shape flag i u v w x yellow triangle 1 11 0.632170 0.988721 0.436498 5.798188 red square 1 15 0.219668 0.001257 0.792778 2.944117 red circle 1 16 0.209017 0.290052 0.138103 5.065034 red square 0 48 0.956274 0.746720 0.775542 7.117831 purple triangle 0 51 0.435535 0.859129 0.812290 5.753095 red square 0 64 0.201551 0.953110 0.771991 5.612050 purple triangle 0 65 0.684281 0.582372 0.801405 5.805148 yellow circle 1 73 0.603365 0.423708 0.639785 7.006414 yellow circle 1 87 0.285656 0.833516 0.635058 6.350036 purple square 0 91 0.259926 0.824322 0.723735 6.854221
Nested JSON objects¶
Additionally, Miller can tabularize nested objects by concatenating keys. If your processing has input as well as output in JSON format, JSON structure is preserved throughout the processing:
mlr --json head -n 2 data/json-example-2.json
[
{
"flag": 1,
"i": 11,
"attributes": {
"color": "yellow",
"shape": "triangle"
},
"values": {
"u": 0.632170,
"v": 0.988721,
"w": 0.436498,
"x": 5.798188
}
},
{
"flag": 1,
"i": 15,
"attributes": {
"color": "red",
"shape": "square"
},
"values": {
"u": 0.219668,
"v": 0.001257,
"w": 0.792778,
"x": 2.944117
}
}
]
But if the input format is JSON and the output format is not (or vice versa), then key-concatenation applies:
mlr --ijson --opprint head -n 4 data/json-example-2.json
flag i attributes.color attributes.shape values.u values.v values.w values.x 1 11 yellow triangle 0.632170 0.988721 0.436498 5.798188 1 15 red square 0.219668 0.001257 0.792778 2.944117 1 16 red circle 0.209017 0.290052 0.138103 5.065034 0 48 red square 0.956274 0.746720 0.775542 7.117831
This is discussed in more detail on the page Flatten/unflatten: JSON vs. tabular formats.
Use --jflatsep yourseparatorhere to specify the string used for key concatenation: this defaults to a single dot.
JSON-in-CSV¶
It's quite common to have CSV data that contains stringified JSON as a column. See the JSON parse and stringify section for ways to decode these in Miller.
JSON Lines¶
JSON Lines is similar to JSON, except:
- UTF-8 encoding must be supported
- There is no outermost
[...] - Each record is on a single line
Miller handles this:
mlr --icsv --ojson head -n 2 example.csv
[
{
"color": "yellow",
"shape": "triangle",
"flag": "true",
"k": 1,
"index": 11,
"quantity": 43.6498,
"rate": 9.8870
},
{
"color": "red",
"shape": "square",
"flag": "true",
"k": 2,
"index": 15,
"quantity": 79.2778,
"rate": 0.0130
}
]
mlr --icsv --ojsonl head -n 2 example.csv
{"color": "yellow", "shape": "triangle", "flag": "true", "k": 1, "index": 11, "quantity": 43.6498, "rate": 9.8870}
{"color": "red", "shape": "square", "flag": "true", "k": 2, "index": 15, "quantity": 79.2778, "rate": 0.0130}
Note that for input data, either is acceptable: whether you use --ijson or --ijsonl, Miller
won't reject your input data for lack of outermost [...], nor will it reject your data for placement
of newlines. The difference is on output: using --ojson, you get outermost [...] and pretty-printed
records; using --ojsonl, you get no outermost [...], and one line per record.
YAML¶
Miller supports YAML as an I/O format in the same spirit as JSON: input can be a single YAML document
that is an object (one record) or an array of objects (one record per element), or multiple YAML
documents separated by --- (each document is an object or array of objects). Output is either one
YAML document per record (with --- between documents) or a single YAML document that is an array
of all records, controlled by the same kind of list-wrap behavior as JSON.
Use --yaml, --iyaml, or --oyaml (or -i yaml / -o yaml). Nested structures and types are
handled like JSON: nested objects become dotted keys when flattened; types are preserved through
the stream.
PPRINT: Pretty-printed tabular¶
Miller's pretty-print format is similar to CSV, but with column alignment. For example, compare
mlr --ocsv cat data/small
a,b,i,x,y pan,pan,1,0.346791,0.726802 eks,pan,2,0.758679,0.522151 wye,wye,3,0.204603,0.338318 eks,wye,4,0.381399,0.134188 wye,pan,5,0.573288,0.863624
mlr --opprint cat data/small
a b i x y pan pan 1 0.346791 0.726802 eks pan 2 0.758679 0.522151 wye wye 3 0.204603 0.338318 eks wye 4 0.381399 0.134188 wye pan 5 0.573288 0.863624
Note that while Miller is a line-at-a-time processor and retains input lines in memory only where necessary (e.g., for sort), pretty-print output requires it to accumulate all input lines (so that it can compute maximum column widths) before producing any output. This has two consequences: (a) Pretty-print output will not work in tail -f contexts, where Miller will be waiting for an end-of-file marker that never arrives; (b) Pretty-print output for large files is constrained by the available machine memory.
See Record Heterogeneity for how Miller handles changes of field names within a single data stream.
Since Miller 5.0.0, you can use --barred or --barred-output with pprint output format:
mlr --opprint --barred cat data/small
+-----+-----+---+----------+----------+ | a | b | i | x | y | +-----+-----+---+----------+----------+ | pan | pan | 1 | 0.346791 | 0.726802 | | eks | pan | 2 | 0.758679 | 0.522151 | | wye | wye | 3 | 0.204603 | 0.338318 | | eks | wye | 4 | 0.381399 | 0.134188 | | wye | pan | 5 | 0.573288 | 0.863624 | +-----+-----+---+----------+----------+
Since Miller 6.11.0, you can use --barred-input with pprint input format:
mlr -o pprint --barred cat data/small | mlr -i pprint --barred-input -o json filter '$b == "pan"'
[
{
"a": "pan",
"b": "pan",
"i": 1,
"x": 0.346791,
"y": 0.726802
},
{
"a": "eks",
"b": "pan",
"i": 2,
"x": 0.758679,
"y": 0.522151
},
{
"a": "wye",
"b": "pan",
"i": 5,
"x": 0.573288,
"y": 0.863624
}
]
Markdown tabular¶
Markdown format looks like this:
mlr --omd cat data/small
| a | b | i | x | y | | --- | --- | --- | --- | --- | | pan | pan | 1 | 0.346791 | 0.726802 | | eks | pan | 2 | 0.758679 | 0.522151 | | wye | wye | 3 | 0.204603 | 0.338318 | | eks | wye | 4 | 0.381399 | 0.134188 | | wye | pan | 5 | 0.573288 | 0.863624 |
which renders like this when dropped into various web tools (e.g. github.comments):
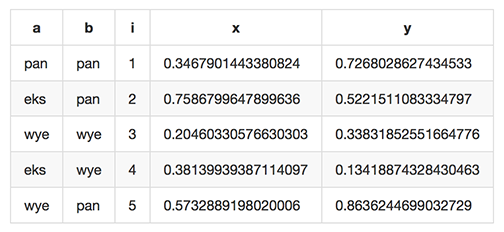
As of Miller 4.3.0, markdown format is supported only for output, not input; as of Miller 6.11.0, markdown format is supported for input as well.
By default, markdown cells are not padded -- which renders identically in a Markdown viewer
but can be awkward to read or maintain as raw text. Use --omd-aligned to pad each column
to a uniform width so the raw markdown source lines up. This flag implies --omd, so you
do not need to pass --omd in addition:
mlr --omd-aligned cat data/small
| a | b | i | x | y | | --- | --- | --- | --- | --- | | pan | pan | 1 | 0.346791 | 0.726802 | | eks | pan | 2 | 0.758679 | 0.522151 | | wye | wye | 3 | 0.204603 | 0.338318 | | eks | wye | 4 | 0.381399 | 0.134188 | | wye | pan | 5 | 0.573288 | 0.863624 |
XTAB: Vertical tabular¶
This is perhaps most useful for looking a very wide and/or multi-column data which causes line-wraps on the screen (but see also ngrid for an entirely different, very powerful option). Namely:
$ grep -v '^#' /etc/passwd | head -n 6 | mlr --nidx --fs : --opprint cat
1 2 3 4 5 6 7 nobody * -2 -2 Unprivileged User /var/empty /usr/bin/false root * 0 0 System Administrator /var/root /bin/sh daemon * 1 1 System Services /var/root /usr/bin/false _uucp * 4 4 Unix to Unix Copy Protocol /var/spool/uucp /usr/sbin/uucico _taskgated * 13 13 Task Gate Daemon /var/empty /usr/bin/false _networkd * 24 24 Network Services /var/networkd /usr/bin/false
$ grep -v '^#' /etc/passwd | head -n 2 | mlr --nidx --fs : --oxtab cat
1 nobody 2 * 3 -2 4 -2 5 Unprivileged User 6 /var/empty 7 /usr/bin/false 1 root 2 * 3 0 4 0 5 System Administrator 6 /var/root 7 /bin/sh
$ grep -v '^#' /etc/passwd | head -n 2 | \
mlr --nidx --fs : --ojson \
label name,password,uid,gid,gecos,home_dir,shell
[
{
"name": "nobody",
"password": "*",
"uid": -2,
"gid": -2,
"gecos": "Unprivileged User",
"home_dir": "/var/empty",
"shell": "/usr/bin/false"
},
{
"name": "root",
"password": "*",
"uid": 0,
"gid": 0,
"gecos": "System Administrator",
"home_dir": "/var/root",
"shell": "/bin/sh"
}
]
DKVP: Key-value pairs¶
Miller's default file format is DKVP, for delimited key-value pairs. Example:
mlr cat data/small
a=pan,b=pan,i=1,x=0.346791,y=0.726802 a=eks,b=pan,i=2,x=0.758679,y=0.522151 a=wye,b=wye,i=3,x=0.204603,y=0.338318 a=eks,b=wye,i=4,x=0.381399,y=0.134188 a=wye,b=pan,i=5,x=0.573288,y=0.863624
Such data is easy to generate, e.g., in Ruby with
puts "host=#{hostname},seconds=#{t2-t1},message=#{msg}"
puts mymap.collect{|k,v| "#{k}=#{v}"}.join(',')
or print statements in various languages, e.g.
echo "type=3,user=$USER,date=$date\n";
logger.log("type=3,user=$USER,date=$date\n");
Fields lacking an IPS will have positional index (starting at 1) used as the key, as in NIDX format. For example, dish=7,egg=8,flint is parsed as "dish" => "7", "egg" => "8", "3" => "flint" and dish,egg,flint is parsed as "1" => "dish", "2" => "egg", "3" => "flint".
As discussed in Record Heterogeneity, Miller handles changes of field names within the same data stream. But using DKVP format, this is particularly natural. One of my favorite use-cases for Miller is in application/server logs, where I log all sorts of lines such as
resource=/path/to/file,loadsec=0.45,ok=true record_count=100, resource=/path/to/file resource=/some/other/path,loadsec=0.97,ok=false
etc., and I log them as needed. Then later, I can use grep, mlr --opprint group-like, etc. to analyze my logs.
See the separators page regarding how to specify separators other than the default equals sign and comma.
DKVPX: Key-value pairs with CSV-style quoting¶
DKVPX is like DKVP but with CSV-style double-quote handling. Keys and values that contain comma, equals, newline, or double-quote are quoted as needed; unquoted keys and values work as in DKVP. Examples: x=1,y=2,z=3 and "x,y"="a,b,c",z=3. Use the --dkvpx flag for input and output. See the separators page for IFS/IPS. For simpler data without special characters, use DKVP instead.
The default is DKVP, not DKVPX, since performance tests show DKVP is approximately 30% faster for cases when quoting is not necessary.
NIDX: Index-numbered (toolkit style)¶
With --inidx --ifs ' ' --repifs, Miller splits lines on spaces and assigns integer field names starting with 1.
This recapitulates Unix-toolkit behavior.
Example with index-numbered output:
cat data/small
a=pan,b=pan,i=1,x=0.346791,y=0.726802 a=eks,b=pan,i=2,x=0.758679,y=0.522151 a=wye,b=wye,i=3,x=0.204603,y=0.338318 a=eks,b=wye,i=4,x=0.381399,y=0.134188 a=wye,b=pan,i=5,x=0.573288,y=0.863624
mlr --onidx --ofs ' ' cat data/small
pan pan 1 0.346791 0.726802 eks pan 2 0.758679 0.522151 wye wye 3 0.204603 0.338318 eks wye 4 0.381399 0.134188 wye pan 5 0.573288 0.863624
Example with index-numbered input:
cat data/mydata.txt
oh say can you see by the dawn's early light
mlr --inidx --ifs ' ' --odkvp cat data/mydata.txt
1=oh,2=say,3=can,4=you,5=see 1=by,2=the,3=dawn's 1=early,2=light
Example with index-numbered input and output:
cat data/mydata.txt
oh say can you see by the dawn's early light
mlr --nidx --fs ' ' --repifs cut -f 2,3 data/mydata.txt
say can the dawn's light
DCF (Debian control file)¶
cat data/sample.dcf
Package: foo Version: 1.0 Depends: libc6 (>= 2.0), libfoo (>= 1.2) Description: A test package. Package: bar Version: 2.0 Recommends: foo Description: Another package.
mlr -i dcf -o json cat data/sample.dcf
[
{
"Package": "foo",
"Version": "1.0",
"Depends": ["libc6 (>= 2.0)", "libfoo (>= 1.2)"],
"Description": "A test package."
},
{
"Package": "bar",
"Version": "2.0",
"Recommends": ["foo"],
"Description": "Another package."
}
]
Data-conversion keystroke-savers¶
While you can do format conversion using mlr --icsv --ojson cat myfile.csv, there are also keystroke-savers for this purpose, such as mlr --c2j cat myfile.csv. For a complete list:
mlr help format-conversion-keystroke-saver-flags
FORMAT-CONVERSION KEYSTROKE-SAVER FLAGS As keystroke-savers for format-conversion you may use the following. The letters c, t, j, l, d, n, x, p, m, and y refer to formats CSV, TSV, JSON, JSON Lines, DKVP, NIDX, XTAB, PPRINT, markdown, and YAML, respectively. DCF is also supported (use --dcf for DCF in and out). | In\out | CSV | TSV | JSON | JSONL | DKVP | NIDX | XTAB | PPRINT | Markdown | YAML | +----------+----------+----------+----------+-------+-------+-------+-------+--------+----------+--------+ | CSV | --c2c,-c | --c2t | --c2j | --c2l | --c2d | --c2n | --c2x | --c2p | --c2m | --c2y | | TSV | --t2c | --t2t,-t | --t2j | --t2l | --t2d | --t2n | --t2x | --t2p | --t2m | --t2y | | JSON | --j2c | --j2t | --j2j,-j | --j2l | --j2d | --j2n | --j2x | --j2p | --j2m | --j2y | | JSONL | --l2c | --l2t | --l2j | --l2l | --l2d | --l2n | --l2x | --l2p | --l2m | --l2y | | DKVP | --d2c | --d2t | --d2j | --d2l | --d2d | --d2n | --d2x | --d2p | --d2m | --d2y | | NIDX | --n2c | --n2t | --n2j | --n2l | --n2d | --n2n | --n2x | --n2p | --n2m | --n2y | | XTAB | --x2c | --x2t | --x2j | --x2l | --x2d | --x2n | --x2x | --x2p | --x2m | --x2y | | PPRINT | --p2c | --p2t | --p2j | --p2l | --p2d | --p2n | --p2x | -p2p | --p2m | --p2y | | Markdown | --m2c | --m2t | --m2j | --m2l | --m2d | --m2n | --m2x | --m2p | | --m2y | | YAML | --y2c | --y2t | --y2j | --y2l | --y2d | --y2n | --y2x | --y2p | --y2m | --y2y | -p Keystroke-saver for `--nidx --fs space --repifs`. -T Keystroke-saver for `--nidx --fs tab`.
Comments in data¶
You can include comments within your data files, and either have them ignored or passed directly through to the standard output as soon as they are encountered:
mlr help comments-in-data-flags
COMMENTS-IN-DATA FLAGS
Miller lets you put comments in your data, such as
# This is a comment for a CSV file
a,b,c
1,2,3
4,5,6
Notes:
* Comments are only honored at the start of a line.
* In the absence of any of the below four options, comments are data like
any other text. (The comments-in-data feature is opt-in.)
* When `--pass-comments` is used, comment lines are written to standard output
immediately upon being read; they are not part of the record stream. Results
may be counterintuitive. A suggestion is to place comments at the start of
data files.
--pass-comments Immediately print commented lines (prefixed by `#`)
within the input.
--pass-comments-with {string}
Immediately print commented lines within input, with
specified prefix. For CSV input format, the prefix
must be a single character.
--skip-comments Ignore commented lines (prefixed by `#`) within the
input.
--skip-comments-with {string}
Ignore commented lines within input, with specified
prefix. For CSV input format, the prefix must be a
single character.
Examples:
cat data/budget.csv
# Asana -- here are the budget figures you asked for! type,quantity purple,456.78 green,678.12 orange,123.45
mlr --skip-comments --icsv --opprint sort -nr quantity data/budget.csv
type quantity green 678.12 purple 456.78 orange 123.45
mlr --pass-comments --icsv --opprint sort -nr quantity data/budget.csv
# Asana -- here are the budget figures you asked for! type quantity green 678.12 purple 456.78 orange 123.45